Knowledge Graph QASP Generation
Master's Thesis — Automated Question-Answer-SPARQL triplet generation from Knowledge Graphs using open-source LLMs
Leuphana University · 2025
Overview
This thesis investigates whether open-source Large Language Models can generate coherent Question-Answer-SPARQL (QASP) triplets directly from Knowledge Graph triples in a single prompt — without fine-tuning or external supervision.
The task combines semantic parsing and natural language generation simultaneously: the model must infer entities, relations and constraints from structured KG triples, and produce a natural language question, a corresponding answer, and a syntactically valid SPARQL query that retrieves that answer from the DBLP knowledge graph. The research explores how design choices — model size, triple representation format, structural metadata, and prompting strategy — affect generation accuracy.
Key Result
87.38% accuracy
Best configuration: Qwen2.5-Coder-32B · hop-info+-linearised-str format · zero-shot · no structural metadata · 10,704 correct QASP triplets generated from 12,250 total
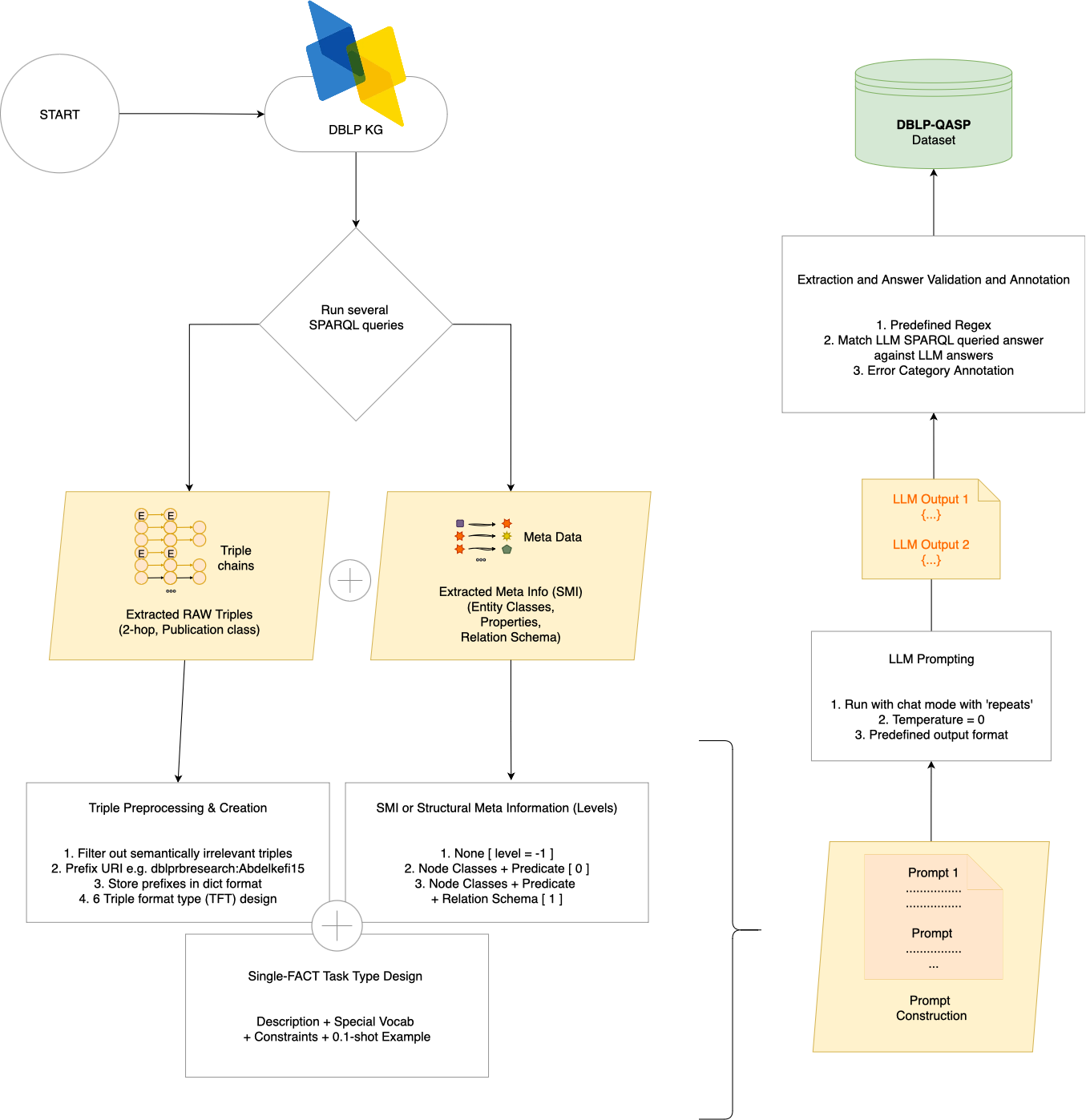
Pipeline
The automated pipeline takes raw KG triples from the DBLP Knowledge Graph (accessed via a Virtuoso SPARQL endpoint) and transforms them through several stages before prompting the LLM.
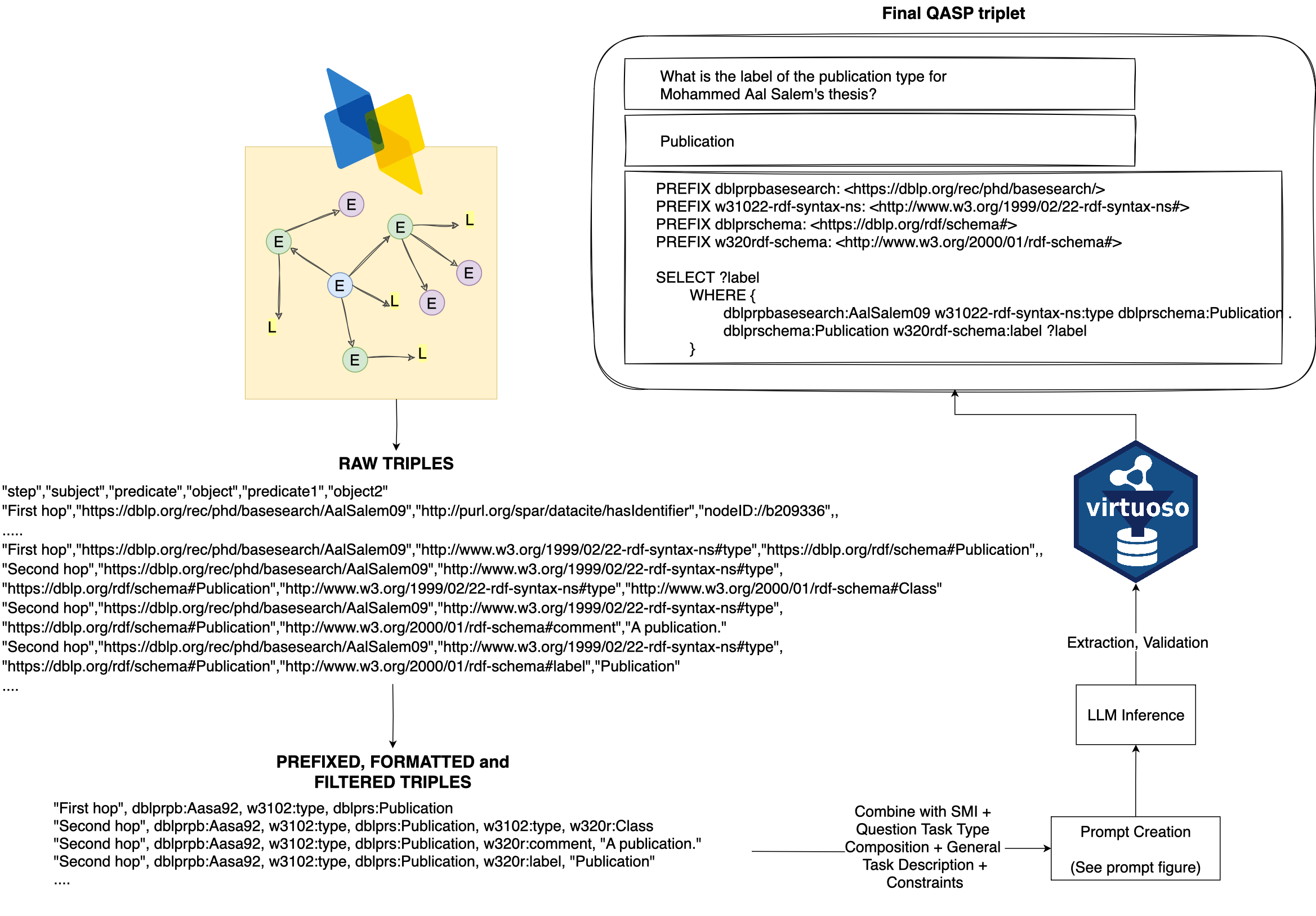
1 — KG Data Extraction
Raw 1-hop and 2-hop triple chains are extracted from the DBLP KG via SPARQL queries targeting the Publication entity class. Structural metadata (node types, predicates, relation schema) is extracted separately for use in higher-level SMI experiments.
2 — Triple Preprocessing
Triples are cleaned and URI-prefixed to reduce token length without losing semantic information. Semantically irrelevant triples (e.g. hasIdentifier) are filtered out. 6 triple format types (TFT) are generated: array, linearised-array, linearised-str, hop-repeat, hop-info+, and special-tokens.
3 — Prompt Construction
Prompts are assembled from the formatted triple chain, optional structural metadata (SMI levels −1, 0, 1), a primitive question task composition (single-fact), and a 0-shot or 1-shot example. The LLM is run in chat mode with temperature 0 and a configurable repeat parameter to generate multiple QASPs per prompt.
4 — Extraction & Validation
Question, answer and SPARQL are extracted from LLM output via regex matching **Question:**, **Answer:**, **SPARQL:**. Each SPARQL is executed against the DBLP KG API — accuracy is measured by whether the queried answer exactly matches the LLM-generated answer.
Experiments
| Experiment | Finding |
|---|---|
| Triple Format Type (TFT) | Linearised string formats outperform array formats across most models. hop-info+-linearised-str is the most consistent top performer. |
| Structural Metadata (SMI) | Counterintuitively, no metadata (SMI = −1) gives the highest accuracy. Adding node class and relation schema context confuses models more than it helps. |
| N-shot prompting | Zero-shot outperforms one-shot for larger models (Gemma, Mistral). Smaller models benefit from examples. One example can introduce bias towards that model's style. |
| Model comparison | Qwen2.5-Coder-32B achieves 87.38% avg. in SMI experiment. Gemma 3 27B and Qwen3 32B are close. Mistral 123B is not proportionally better than 32B models. |
Models Evaluated
| Model | Parameters | Best Avg. Accuracy |
|---|---|---|
| Qwen2.5-Coder-32B-Instruct | 32B | 87.38% |
| Gemma 3 27B Instruct | 27B | 72.2% |
| Qwen3 32B | 32B | 71.4% |
| Mistral Large Instruct 123B | 123B | 63.3% |
| Codestral 22B | 22B | 32.2% |
| Llama 3.1 8B Instruct | 8B | 14.4% |
Stack
| Layer | Technology |
|---|---|
| Language | Python 3 · Poetry |
| LLM API | GWDG HPC interface (open-source models via API) |
| Knowledge Graph | DBLP KG · Virtuoso SPARQL endpoint |
| Data | DBLP-QASP dataset — 10,704 validated QASP triplets |