Learning on Attribute-Missing Graphs — SAT
Deep Learning ResearchAnalysing Networks · Prof. Dr. Ulf Brefeld · Leuphana Universität Lüneburg
The Problem
Graphs in the real world are messy. Some nodes have rich feature vectors, some have partial data, and some have nothing at all. This last case — attribute-missing graphs — is the hardest and least studied. Standard GNNs break down when a node has zero attributes: you can't just impute zeros or averages.
The missing nodes often sit in structurally distinct parts of the graph, creating discontinuity between observed and unobserved regions, compounded by heterogeneity across node classes. The goal: given adjacency matrix A and partial attributes XO, recover the missing XU.
Foundations
Three building blocks underpin SAT:
- —Autoencoders — compress data into a latent code and reconstruct it, minimising MSE. Simple, but the latent space is unstructured.
- —Variational Autoencoders (VAE) — encoder outputs μ and σ; sample drawn as
z = μ + σ ⊙ ε. KL divergence keeps the posterior close to a Gaussian prior — smooth, generative latent space. - —GANs — adversarially pit a generator against a discriminator. SAT borrows this to align latent distributions without a fixed KL target.
The Model — Structure Attribute Transformer (SAT)
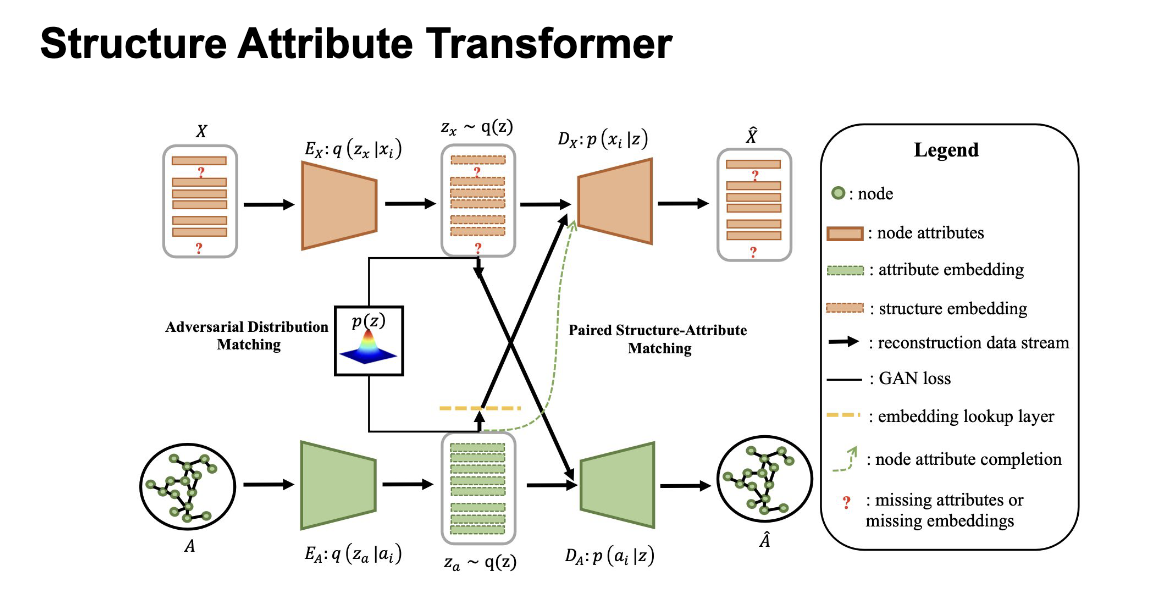
SAT runs two parallel VAE pipelines — one over node attributes X, one over graph structure A — tied together by two mechanisms:
- —Paired Structure-Attribute Matching (PSAM) — forces both latent spaces to be compatible. Each encoder can decode into the other modality. Reconstruction loss has four streams: self-reconstruct attributes, self-reconstruct structure, and two cross-streams weighted by λ_c.
- —Adversarial Distribution Matching (ADM) — replaces KL regularisation. A single shared discriminator pushes both z_x and z_a toward the same prior p(z) via a GAN objective.
Training & Inference
Seven steps, repeated until convergence:
- Encode XO and AO into latent codes
- Embedding lookup
- Sample from prior for adversarial matching
- Run PSAM + ADM
- Compute cost
- Update via Adam/SGD
- Repeat
After training, sample Z_AU from Z_A to restore missing node attributes and predict missing links.
Presentation Structure

Open Research Threads
- —Variational inference theory — tightening the ELBO bound
- —GAN mode collapse — stability of adversarial training in latent space
- —GNN architectures — comparing SAT against GAT (graph attention networks)
- —Time complexity of SAT at scale — experimental benchmarks on large sparse graphs